The thread sandwich pattern
A common code structure pattern for multi-threading is the sandwich pattern
Introduction
When writing multi-threading code using low level primitives, a difficult issue that developers face is how to structure code to avoid a large monolithic chunk of code and break it instead into smaller units:
- That can be thoroughly reasoned about the correctness
- That have a clear purpose and separate threading concerns from application functionality
- That breaks circular references when several communicating threads are involved
- That can be unit tested
The sandwich pattern is a way of structuring multi-threading code which breaks the threading concerns into several entities. The core application function is sandwiched between a thread control layer that manages pending workload and the threading layer that manages the actual thread lifetime.
The example below mimics two jugglers throwing balls to each other. The “balls”
are just ints with values 1 and 2 initially, then 3 as well later.
The dependencies between the involved objects looks like this:
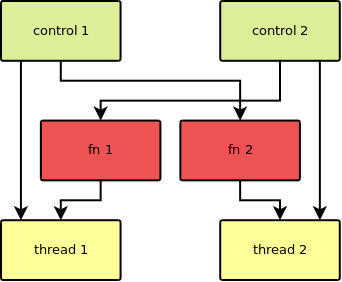
The application function is in this case “when you handle a ball, throw it
to the other juggler”. In the code below it depends on the control layer for
the other juggler (where the ball will be thrown) and it’s implemented as
lambdas inside the main function body (due to it’s simplicity in this
example).
The control layer manages the balls to be handled by the juggler. In the
code below it’s implemented by the thread_control template class that holds a
queue of some data type, a flag used for stopping the thread, and a mutex and
condition_variable for synchronization. This class is instantiated in the
main function body for int as the data type. It also has methods to
manipulate that data:
post_data: to throw a ball. This would be called from a different thread.serve: to serve the balls. This would be called from the underlying thread and would receive the application function.stop_servingto set the stop flag. This would be called from some thread that manages the life of the jugglers thread, the main thread in this case.raw_data: to access the data with no synchronization. This could be useful for scenarios where the user knows that synchronization is not required.
The thread layer handles starting and stopping the thread and runs the
processing loop. In the code below it’s implemented by the stoppable_thread
template class. The constructor and destructor of stoppable_thread manage the
lifetime of the native thread.
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
#include <chrono>
#include <condition_variable>
#include <deque>
#include <iostream>
#include <mutex>
#include <thread>
template<typename DataType>
class thread_control
{
std::deque<DataType> q_;
bool stop_{ false };
std::mutex m_;
std::condition_variable cv_;
public:
// could also have an overload that moves
void post_data(const DataType & x)
{
{
std::scoped_lock lock(m_);
q_.push_back(x);
}
cv_.notify_one();
}
template<typename Fn>
void serve(Fn fn)
{
while (true)
{
DataType x;
{
std::unique_lock<std::mutex> lock(m_);
cv_.wait(lock, [&]{ return !q_.empty() || stop_; });
if (stop_) return;
x = std::move(q_.front());
q_.pop_front();
}
fn(x);
}
}
void stop_serving()
{
{
std::scoped_lock lock(m_);
stop_ = true;
}
cv_.notify_one();
}
std::deque<DataType> & raw_data()
{
return q_;
}
};
template<typename DataType>
class stoppable_thread
{
thread_control<DataType> & tc_;
std::thread td_;
public:
template<typename Fn>
stoppable_thread(thread_control<DataType> & tc, Fn fn) :
tc_{ tc },
td_{ [&, fn]{ tc_.serve(fn); } }
{}
~stoppable_thread()
{
tc_.stop_serving();
td_.join();
}
};
int main()
{
thread_control<int> juggler_control_1;
thread_control<int> juggler_control_2;
// can use raw_data, threads don't run yet
juggler_control_1.raw_data().push_back(1);
juggler_control_2.raw_data().push_back(2);
auto juggler_fn_1 = [&tc = juggler_control_2](int x) { tc.post_data(x); };
auto juggler_fn_2 = [&tc = juggler_control_1](int x) { tc.post_data(x); };
{
stoppable_thread<int> juggler_thread_1(juggler_control_1, juggler_fn_1);
stoppable_thread<int> juggler_thread_2(juggler_control_2, juggler_fn_2);
// threads run, use post_data
juggler_control_1.post_data(3);
std::this_thread::sleep_for(
std::chrono::seconds(2));
}
// can use raw_data again, threads don't run any more
for (int x : juggler_control_1.raw_data())
{
std::cout << "Juggler 1 has ball " << x << '\n';
}
for (int x : juggler_control_2.raw_data())
{
std::cout << "Juggler 2 has ball " << x << '\n';
}
}
// Possible output:
//Juggler 2 has ball 1
//Juggler 2 has ball 3
//Juggler 2 has ball 2
The code above is an example. I’m going to describe a few details that would hopefully disambiguate what aspects are important, and which are merely accidental.
Similarities to asio io_context
The thread_control is similar to the asio::io_context object. io_contex
has similar methods to post work to a queue, to process work from the queue and
to stop processing. In that case the queue of work is implemented using IO
completion ports on Windows for example.
Alternatively one could have the thread_control as a structure with public
member variables and make the member functions as standalone functions. In that
case raw_data() would no longer be required. In more complex cases, where the
queue was more complex I separated it out of the other items that are required
for the thread synchronization (mutex, condition variable and stop flag).
Instantiation
What creates the sandwich pattern is that dependencies are provided in constructors. This way:
- The control needs to be instantiated first
- Then the function (in this case a lambda) takes in the constructor a reference of a control instance (in this case the control of another thread)
- The underlying thread (
stopable_threadin this case) takes in the constructor a reference to the control instance and makes a copy of the function
We achieve customization using dependencies injected at construction without using inheritance. Inheritance is sometimes a trap.
Object lifetime
The object lifetime is significant in several places above. It’s controlled in the example above explicitly by having additional pairs of curly brackets or implicitly by function scope.
In main we use a pair of curly brackets to control the scope of the running
threads. Outside that scope the threads are not running, so we can access using
raw_data without any synchronization. We can reason about the correctness of
this using synchronizes-with terminology for std::thread
construction and join. These curly brackets are there just to make a
interesting example, we rarely need create an explicit scope for
stoppable_thread, different from the one for thread_control.
Inside the serve function we control the lifetime of the unique_lock
variable so that the mutex is unlocked for the duration of the processing
function. This allows another thread to post additional data in the meantime.
In stop_serving and post_data we control the lifetime of the scoped_lock
variable so that the mutex is unlocked before we call notify_one on the
condition_variable.
Calling notify_one on the condition_variable before the mutex is unlocked
would not be ideal because the thread that is notified can’t wake up and
proceed from waiting on the condition_variable: it will have to go back to
sleep until the mutex is unlocked. But in practice it will work, and I
would expect that the threading libraries will deal with the not-ideal scenario
without too much performance loss.
However notice that before join-ing the thread we really need to ensure that
the mutex is unlocked, else the thread can’t lock it to check the stop flag.
We can’t put the code from stop_serving directly into the destructor of the
stopable_thread and get rid of the explicit scope the lock.
Shutting-down
At some point the worker threads need to stop. In a real application this would be when the user closes an application or when a daemon/service needs to stop. In this dummy example we used a short sleep delay on the main thread.
We use the stopable_thread class because some quirks on the behaviour of
std::thread. It terminates if not joined (i.e. if the native
thread is still running by the time the std::thread destructor is called). If
that were not the case, the native thread might still continue to access data
that would go out of scope (such as the thread_control in our example)
corrupting and crashing in ways that are difficult to diagnose.
Exceptions
Exception handling is a particular case where some aspects in the code above are important, whereas in other cases there is simplification for the sake of the example.
By properly using RAII in stoppable_thread, if we created the first thread in
main, but there are errors creating the second one which throw an exception,
the destructor of the first thread will take care of stopping it. This assumes
that you’ll add a catch block around the main body, which I’ve omitted for
brevity. This is normal RAII related exception handling.
It turns out that locking a mutex can throw. That can happen “when errors
occur, including errors from the underlying operating system that would prevent
lock from meeting its specifications”.
The code above locks a mutex in stop_serving. That is called from the
stoppable_thread destructor. Destructors are implicitly noexcept. Throwing
from a noexcept function terminates the process. So if locking the mutex
throws, the process will be terminated. This is unintuitive, but important in
the code above. The rationale is similar to the std::thread termination case
if not joined: if we started threads, but can’t communicate to
stop them, there is no recovery from this situation.
The same is the case for unique_lock inside serve. If the mutex throws in
lock it is not handled by the application code and will terminate the
process. The rationale is that if we can’t lock the mutex, we can’t
communicate to stop the thread, we might as well terminate, there is no
recovery.
Data loss and flow control
An application has to have a strategy to either deal with data loss or ensure that it does not happen.
This is the issue of what to do when processing the item taken from the queue
fails with an exception (i.e. from within the fn() call inside serve()).
Some options are:
- Terminate. This is what the example does, for brevity reasons. As it is,
should
fn()exit with an exception, it is not handled by the application code and will terminate the process. This is appropriate for non-critical applications where the error is very unlikely. In the example above it would be an exception frompost_data()e.g. out of memory when adding to thedequeor exception from thelock()of themutex. - Retry. One problem with this approach is that it’s usually uncertain that retrying will not encounter the same error again, leading to the risk of an infinite retry loop, so at least the retry is sometimes done on a timer to only retry periodically, rather than in a tight loop.
- Ignore and continue. This leads to data loss. Depending on how far the processing goes, it might mean that data was taken out of the queue, but if something else waits for a response, the response will not arrive.
- Ensure data loss won’t happen. This is sometimes possible, either because the processing is guaranteed to not have exceptions or, in the case where a response is expected, ensure that enough is allocated by the sender so that at least an error can be propagated back.
An application also has to have a strategy for flow control. This is often related to the data loss strategy. This is the issue of how to deal with pending work accumulating faster than it is processed. This falls from the fact that in systems that involve two communicating parties, it is bound that one will be slower than the other.
Some options when too much pending work accumulates are:
- Terminate. Terminating the process might be appropriate for non-critical applications. Also it might work in scenarios where the termination is partial e.g. a connection is closed and a new connection is started. In either case this might lead to data loss for the existing pending work.
- Only keep last value. This is appropriate for cases where state information is sent, and only the last state matters. E.g. when tracking the number of people in a room, if the number of people change faster than it can be processed, it might be fine to only update to the last value of people in a room, loosing data about intermediate states.
- Ensure it does not happen. Sometimes there is a natural limit to the amount of pending work. In our simple jugglers example there will be at most 3 items in the queue.
An application also has to deal with data left in the queue when threads stop. At least the data has to be freed and not cause resource/memory leaks.
Some options are:
- Discard (this is the simplest one).
- Process, at least in a limited way. E.g. if the data refers to a network connection, one could stop accepting further connections, send an error message and close the existing connection, then resume the shutdown sequence.
Note that if you run the sample application several times, it will tend to print balls left in the second juggler queue. The reason is that the second juggler thread is destroyed, hence stopped, first. While the second juggler thread is stopping, the first juggler thread is busy posting data to the second juggler’s queue.
On testing
The separation in different entities makes it easier to test. The function
layer can be tested using single threaded applications, whereas for the
thread_control and stoppable_thread tests can also be written, such as the
example below that tests that if two items are posted, they are processed in
order.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
TEST(can_process_two_items)
{
int processed_count = 0;
thread_control<bool> main_tc;
{
thread_control<int> tc;
auto fn =[&main_tc, &processed_count](int x) {
ASSERT_EQ(processed_count, x);
++processed_count;
if (2 == processed_count) {
main_tc.stop_serving();
}
};
stoppable_thread<int> st(tc, fn);
tc.post_data(0);
tc.post_data(1);
main_tc.serve([](bool){});
}
ASSERT_EQ(2, processed_count);
}
Templates
I’ve used template classes for thread_control and stoppable_thread. That
was just to help imagine that they can be used to hold arbitrary data, not just
ints.
On the other side thread_control::serve and the constructor of
stoppable_thread are template functions so that they can efficiently receive
any function (lambdas in our example) without additional memory allocations
that std::function will required. That is a useful technique. But for long
running threads the cost that will probably matter would be the efficiency of
operations inside the thread loop in serve.
Structuring applications
A common anti-pattern is structuring applications so that all the functionality
about Xyz is dealt by a large monolithic class XyzManager that does all
things Xyz related, including running it’s own threads. Then the application
is composed out of such classes. This is a anthropomorphic view of the
world which results in circular references between these
classes, often badly solved via start/stop style methods.
A better approach is to declare the threads (either single or in thread pools)
upfront and describe the functions to be run on such threads, as it’s done in
the code example above. This breaks the circular references by defining
additional entities, such as the thread_control class that holds pending
work.
Bugs
Update 2023-04-14:
The original code in this article had a bug that has been brought to my attention. Spot the difference:
1
2
3
4
5
6
7
8
9
10
11
12
13
// incorrect
template<typename Fn>
stoppable_thread(thread_control<DataType> & tc, Fn fn) :
tc_{ tc },
td_{ [&]{ tc_.serve(fn); } }
{}
// correct
template<typename Fn>
stoppable_thread(thread_control<DataType> & tc, Fn fn) :
tc_{ tc },
td_{ [&, fn]{ tc_.serve(fn); } }
{}
The issue is that the incorrect code uses in the lambda a reference to the
temporary fn from the stoppable_thread constructor, leading to intermittent
crashes. The small difference in the correct code captures the fn by copy so
that serve gets this copy rather than the reference that is potentially
dangling by the time the thread function of td_ actually runs.
The bug shows how easy it is to make mistakes in multithreaded code. I believe
that separating code in low level one, like thread_control and
stoppable_thread, from code that generally does not have to care about the
low level details, like the juggler_fn_1 and juggler_fn_2 functions that
only have to care about calling the correct function, e.g. call post_data
that itself will take care of the low level synchronization issues, is the
right approach that makes it easier to deal with the complexities of
multithreading and ensure correctness.
A bug like the one above is easier to find and fix when dealing with smaller entities of code rather than when dealing with monolithic large entities.
Conclusion
Writing multi-threaded code is more complex than single-threaded code. The thread sandwich pattern is not the only way to tackle multi-threaded code, but the code above and the many issues to consider discussed above set a minimal standard for writing multi-threaded code.
References
Buggy threading code using inheritance
Rationale for std::thread destructor terminating
http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2008/n2802.html
Anthropomorphic design anti-pattern
Start/stop methods anti-pattern