How vector works - array and positions
What we need to know about C arrays so that we get the C++ vector.
Introduction
In the “How vector works” series of blogs I’m going to cover how I look at the
std::vector, the default container in C++. The first article in the series
looks at arrays, the data structure that the vector competes with and look at
positions in an array and how they generalise to iterators and ranges.
Array
An array is a memory contiguous sequence of values.
With an array we need to know where it starts. For that, a pointer is usually
used, e.g. begin, which points to the memory location of the first value in
the array.
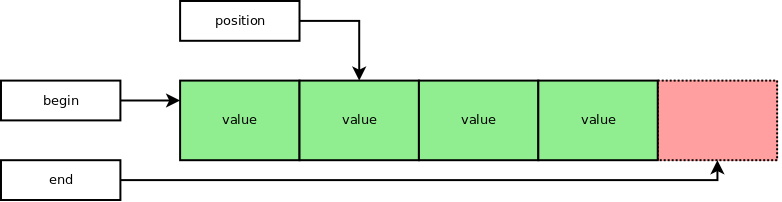
To identify the position of a value in an array we need a pointer to that value.
Incrementing or decrementing the pointer advances by one the position forward or backward. To do that, the code generated by the compiler adds or subtracts from the pointer the size of an element in the array.
Similarly to advance the pointer by N, the code generated by the compiler multiplies the size of an element by N and adjusts the pointer accordingly.
In practical terms, the C/C++ syntax accepts the name of an array e.g.
some_array as a pointer to the first value. The syntax provides the index
operator: some_array[i] will start with the pointer to the beginning of the
array and advance it i times the size of an element in the array. Another way
of getting the pointer to the array is to take the address of the first element
(at index 0): &some_array[0].
Three options for sequence length
We also need to know how long the sequence is. For that we either need to:
- Use another pointer (in general two pointers can define a range)
- Use or know the size (e.g. at compile time)
- Use a special value (a sentinel, e.g.
0for sequences of characters). This requires the array to be one value bigger.
Two pointers
I’m going to focus on the option of using two pointers for the range of values
in an array: begin and end.
std::begin(some_array) and std::end(some_array) can be used to obtain the
begin and end pointers for some C array.
Despite the name, end does not point to the last element in the array,
instead it is advanced one position after the last element in the array,
hence the position is referred to one past the last.
Rules of the language going as far as C allow us to use a pointer like end,
as long as we don’t dereference it. The end must not be dereferenced, it does
not point to a value. That’s another way of saying that we should not read from
or write to the address pointed by end.
This mechanism allows us to represent empty arrays where begin is equal to
end.
The mechanism to traverse the array involves a loop similar to the one below:
1
2
3
4
for (auto it = std::begin(some_array); it != std::end(some_array); ++it)
{
// process value obtained by dereferencing `*it`
}
Position which points to or between
The two pointers are positions. The position is a more fundamental element of vocabulary then a range. There are two ways of looking at a pointer representing a position.
In the hardware view the pointer points to a memory location, e.g. the first byte of a value. This captures best the ideas like:
- the
endpoints to one past the last, which should not be dereferenced [begin, end)is the representation of a closed-open mathematical range which includes the value pointed bybegin, but excludes the value pointed byend.
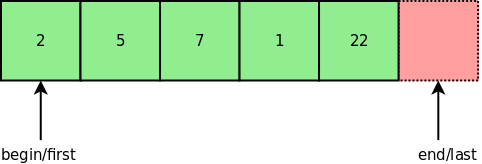
Another view is to think that positions point in between the values in the sequence. Sean Parent uses this representation.
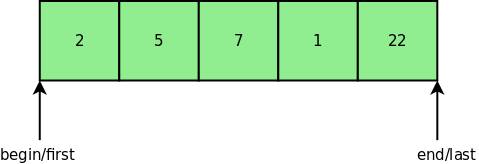
In both views they illustrate the issue that for a sequence of N elements,
N + 1 positions are required. When designing data structures, this requires
attention to the number of bits required for positions for a certain maximum
number of elements.
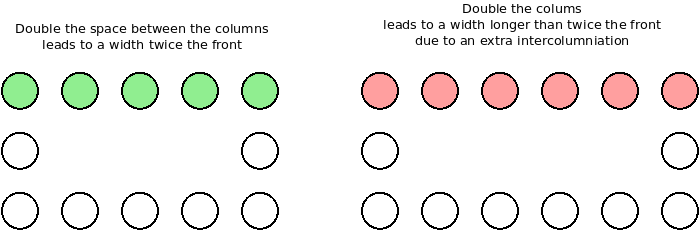
Ultimately it’s a problem not limited to arrays. For a fence of 50m, with fence panels of 10m, 6 posts are required, not 5. As old of 1st century BC, Vitruvius in his De Architectura book III, chapter 4 advices that to build a temple of a length twice the front width, one should use twice the space between the columns (intercolumniation), not twice the columns. Or else he warns:
For those who made double the number of the columns seem to be at fault because in the length one more intercolumniation than is necessary seems to occur.
Pointer and size
Using two pointers is logically equivalent to using a pointer and size (because
of the pointer arithmetic increments in sizeof(value):
- the
sizecan be calculated byend - begin - the
endcan be calculated bybegin + size
We can convert between the two choices as required, when there is a gain to be made on the number of calculations.
For situations where we consume from the sequence, it requires to update both the pointer and the remaining size, so using two pointers is better for this scenario.
The mechanism to traverse the array using a pointer and size involves a loop similar to the one below:
1
2
3
4
5
for (size_t i = 0; i != std::size(some_array); ++i)
{
// process value obtained by dereferencing `*(begin + i)`
// or equivalently access `some_array[i]`
}
The disadvantage is that two calculations are required for each iteration: one
to increment i, and another to calculate the current pointer position
begin + i, though it’s such a common pattern that the processor might help
with it (e.g. by addressing modes in the instruction set).
The pointer and size approach is useful for divide (in half) and conquer (e.g.
partition_point, lower_bound etc.), because the half is easily obtained by
dividing the size.
std::begin(some_array) and std::size(some_array) can be used to obtain the
begin pointer and the number of elements for some C array.
Pointer and sentinel
Using a sentinel is the approach used by C-style zero terminated strings, the zero terminator being the sentinel.
The mechanism to traverse the array involves a loop similar to the one below:
1
2
3
4
for (auto it = std::begin(some_array); *it != 0 ; ++it)
{
// process value obtained by dereferencing `*it`
}
Obviously care needs to be taken to ensure that the sentinel exist and will be met before going past the array size.
Generalize to iterators and ranges
The three options above (two pointers, pointer and size, pointer and sentinel) can be used to define additional ranges, not just the range of the whole array.
The range can be expressed using two postions.
If so, by convention, first and last are used for the positions defining
the range, as opposed to begin and end which refer to the whole range of a
array. All the issues about end apply to last e.g., despite its name,
last does not point to the last element in the range, but one past last.
Or the range can be wrapped into a range object, with member(s) for the position(s) involved.
The positions can be generalized for other containers than arrays, that’s what the iterators are for sequential data structures. In some cases they might loose certain features e.g. array iterators have the ability for arbitrary jumps (random iterators), while lists only have the ability to advance efficiently one position at a time.
When the sentinel approach is generalized (e.g. to deal with an input iterator reading from a file until file end) in order to be able to use it with generic algorithms it might be needed to:
- use a type for most positions (including
begin`) - but have a different type for the
end` iterator, e.g. an empty type with no data - override the equality comparing between the type of
beginand type ofende.g. to check if the value at pointer is the sentinel, or if the end of file was reached - generic functions take the range positions as arguments of different type
(for
begin/fistandend/last), but return the type ofbeginwhen they return a position
Const and reverse iterators
Iterators that allow getting a value, but not changing it are called const iterators.
For a const array std::begin(some_array) and std::end(some_array) are
overloaded to return const iterators. For cases where the array is not const
use std::cbegin(some_array) and std::cend(some_array) to explicitly
retrieve const iterators.
To traverse an array in the reverse order you can use reverse iterators.
To obtain the range of an array as reverse iterator you can use
std::rbegin(some_array) and std::rend(some_array) (and their const
counterparts std::crbegin(some_array) and std::crend(some_array)).
Incrementing a reverse operator actually goes a position backwards rather than forwards.
1
2
3
4
5
for (auto it = std::rbegin(some_array); it != std::rend(some_array) ; ++it)
{
// process value obtained by dereferencing `*it`
// the array is traversed in reverse order
}
Note that for an array the reverse iterators point one past the element that they will access. The hardware view of positions is more useful in this case.
E.g. std::rbegin(some_array) has and underlying pointer to one past the last
element in the array like std::end(some_array) just like
std::end(some_array), but, when std::rbegin(some_array) is dereferenced,
will decrement the pointer and access the last element in the array, unlike
std::end(some_array) which should not be dereferenced.
Notes
Beware of idioms using more elements than required. E.g. functions that require an array, an offset AND a length as arguments in order to pass a array range are not minimalistic. That might be required only because of language limitations (e.g. Java). Two pointers (or a pointer and length) is enough.
Similarly, when we access an array using an index e.g. some_array[i], behind
the scenes the array start pointer is incremented i positions to obtain the
pointer for the value at index i. If we need to store, or pass as a function
argument, or return from a function the position for the value at index i, a
single pointer is enough. We don’t need to store/pass both a pointer to the
beginning of the array AND an index.